
O que mudou no Top 10 para 2021
Existem três novas categorias, quatro categorias com alterações de nomenclatura e escopo e alguma consolidação no Top 10 para 2021.

A01: 2021-Controle de acesso quebrado move-se para cima a partir da quinta posição; 94% dos aplicativos foram testados para alguma forma de controle de acesso quebrado. Os 34 CWEs mapeados para Broken Access Control tiveram mais ocorrências em aplicativos do que qualquer outra categoria.
A02: 2021-Falhas criptográficas sobe uma posição para a 2ª posição, anteriormente conhecida como Exposição de dados confidenciais, que era um sintoma amplo, e não uma causa raiz. O foco renovado aqui está nas falhas relacionadas à criptografia, que geralmente levam à exposição de dados confidenciais ou comprometimento do sistema.
A03: 2021-Injeção desliza para a terceira posição. 94% dos aplicativos foram testados para alguma forma de injeção, e os 33 CWEs mapeados nesta categoria têm o segundo maior número de ocorrências em aplicativos. Cross-site Scripting agora faz parte desta categoria nesta edição.
A04: 2021-Design inseguro é uma nova categoria para 2021, com foco nos riscos relacionados a falhas de design. Se quisermos genuinamente “ir para a esquerda” como setor, isso exige mais uso de modelagem de ameaças, padrões e princípios de design seguros e arquiteturas de referência.
A05: 2021-Configuração incorreta de segurança passou de # 6 na edição anterior; 90% dos aplicativos foram testados para algum tipo de configuração incorreta. Com mais mudanças em software altamente configurável, não é surpreendente ver essa categoria subir. A antiga categoria de XML External Entities (XXE) agora faz parte desta categoria.
A06: 2021-Componentes vulneráveis e desatualizados era anteriormente intitulado Usando componentes com vulnerabilidades conhecidas e é o número 2 na pesquisa do setor, mas também tinha dados suficientes para chegar aos 10 principais por meio de análise de dados. Esta categoria passou da 9ª posição em 2017 e é um problema conhecido que temos dificuldade em testar e avaliar o risco. É a única categoria que não possui CVEs mapeados para os CWEs incluídos, portanto, uma exploração padrão e pesos de impacto de 5,0 são considerados em suas pontuações.
A07: 2021-Identification and Authentication Failures (Falhas de identificação e autenticação 2021) anteriormente quebrou a autenticação e está deslizando para baixo da segunda posição, e agora inclui CWEs que estão mais relacionados a falhas de identificação. Essa categoria ainda é parte integrante do Top 10, mas a maior disponibilidade de estruturas padronizadas parece estar ajudando.
A08: 2021-Falhas de software e integridade de dados é uma nova categoria para 2021, com foco em fazer suposições relacionadas a atualizações de software, dados críticos e pipelines de CI / CD sem verificar a integridade. Um dos maiores impactos ponderados dos dados CVE / CVSS mapeados para os 10 CWEs nesta categoria. A desserialização insegura de 2017 agora faz parte dessa categoria maior.
A09: 2021 – Falhas de registro e monitoramento de segurança eram anteriormente Registro e monitoramento insuficientes e foi adicionado a partir da pesquisa do setor (nº 3), passando do nº 10 anterior. Esta categoria foi expandida para incluir mais tipos de falhas, é um desafio para testar e não está bem representada nos dados CVE / CVSS. No entanto, as falhas nesta categoria podem impactar diretamente a visibilidade, o alerta de incidentes e a perícia.
A10: 2021-Server-Side Request Forgery adicionado da pesquisa do setor (nº 1). Os dados mostram uma taxa de incidência relativamente baixa com cobertura de teste acima da média, junto com classificações acima da média para potencial de exploração e impacto. Essa categoria representa o cenário em que os profissionais da indústria estão nos dizendo que isso é importante, embora não esteja ilustrado nos dados neste momento.
Metodologia
Esta parte do Top 10 é mais baseada em dados do que nunca, mas não cegamente baseada em dados. Selecionamos oito das dez categorias de dados contribuídos e duas categorias de uma pesquisa do setor em alto nível. Fazemos isso por uma razão fundamental: olhar para os dados fornecidos é olhar para o passado. Os pesquisadores do AppSec levam tempo para encontrar novas vulnerabilidades e novas maneiras de testá-las. Leva tempo para integrar esses testes em ferramentas e processos. No momento em que podemos testar com segurança uma fraqueza em escala, provavelmente já se passaram. Para equilibrar essa visão, usamos uma pesquisa do setor para perguntar às pessoas na linha de frente o que elas veem como pontos fracos essenciais que os dados podem não mostrar ainda.
Existem algumas mudanças críticas que adotamos para continuar a amadurecer o Top 10.
Como as categorias são estruturadas
Algumas categorias mudaram em relação à edição anterior do OWASP Top Ten. Aqui está um resumo de alto nível das mudanças de categoria.
Os esforços anteriores de coleta de dados concentraram-se em um subconjunto prescrito de aproximadamente 30 CWEs com um campo solicitando descobertas adicionais. Aprendemos que as organizações se concentrariam principalmente nesses 30 CWEs e raramente acrescentariam outros CWEs que vissem. Nesta iteração, nós o abrimos e apenas pedimos os dados, sem restrição de CWEs. Pedimos o número de aplicativos testados para um determinado ano (começando em 2017) e o número de aplicativos com pelo menos uma instância de um CWE encontrado em teste. Esse formato nos permite rastrear a prevalência de cada CWE na população de aplicativos. Ignoramos a frequência para nossos propósitos; embora possa ser necessário para outras situações, ele apenas oculta a prevalência real na população de aplicação. Se um aplicativo tem quatro instâncias de um CWE ou 4, 000 instâncias não fazem parte do cálculo para os 10 principais. Passamos de aproximadamente 30 CWEs para quase 400 CWEs para analisar no conjunto de dados. Planejamos fazer análises de dados adicionais como um suplemento no futuro. Este aumento significativo no número de CWEs exige mudanças na forma como as categorias são estruturadas.
Passamos vários meses agrupando e categorizando os CWEs e poderíamos ter continuado por mais meses. Tivemos que parar em algum ponto. Existem causas raiz e tipos de sintoma de CWEs, em que os tipos de causa raiz são como “Falha criptográfica” e “Configuração incorreta” em contraste com tipos de sintoma como “Exposição de dados confidenciais” e “Negação de serviço”. Decidimos focar na causa raiz sempre que possível, pois é mais lógico para fornecer orientação de identificação e correção. Focar na causa raiz sobre o sintoma não é um conceito novo; o Top Ten tem sido uma mistura de sintoma e causa raiz . ; estamos simplesmente sendo mais deliberados sobre isso e convocando-o. Há uma média de 19,6 CWEs por categoria nesta parcela, com os limites inferiores de 1 CWE para A10: 2021-Server-Side Request Forgery (SSRF) a 40 CWEs em A04: 2021-Design inseguro . Essa estrutura de categorias atualizada oferece benefícios adicionais de treinamento, pois as empresas podem se concentrar em CWEs que façam sentido para uma linguagem / estrutura.
Como os dados são usados para selecionar categorias
Em 2017, selecionamos categorias por taxa de incidência para determinar a probabilidade e, em seguida, as classificamos por discussão da equipe com base em décadas de experiência em Explorabilidade, Detectabilidade (também probabilidade) e Impacto técnico. Para 2021, queremos usar dados para explorabilidade e impacto, se possível.
Baixamos o OWASP Dependency Check e extraímos o CVSS Exploit e as pontuações de impacto agrupadas por CWEs relacionados. Foi necessário um pouco de pesquisa e esforço, pois todos os CVEs têm pontuações CVSSv2, mas há falhas no CVSSv2 que o CVSSv3 deve corrigir. Após um determinado momento, todos os CVEs também recebem uma pontuação CVSSv3. Além disso, os intervalos de pontuação e fórmulas foram atualizados entre CVSSv2 e CVSSv3.
No CVSSv2, tanto o Exploit quanto o Impact poderiam ser até 10,0, mas a fórmula os derrubaria para 60% para o Exploit e 40% para o Impact. No CVSSv3, o máximo teórico foi limitado a 6,0 para o Exploit e 4,0 para o impacto. Com a ponderação considerada, a pontuação de impacto aumentou, quase um ponto e meio em média no CVSSv3, e a explorabilidade caiu quase meio ponto abaixo em média.
Existem 125k registros de um CVE mapeado para um CWE nos dados NVD extraídos da verificação de dependência OWASP, e há 241 CWEs exclusivos mapeados para um CVE. Mapas CWE de 62k têm uma pontuação CVSSv3, que é aproximadamente metade da população no conjunto de dados.
Para os dez primeiros, calculamos as pontuações médias de exploração e impacto da seguinte maneira. Agrupamos todos os CVEs com pontuações CVSS por CWE e ponderamos a exploração e o impacto marcados pela porcentagem da população que tinha CVSSv3 + a população restante de pontuações CVSSv2 para obter uma média geral. Mapeamos essas médias para os CWEs no conjunto de dados para usar como pontuação de Exploração e Impacto para a outra metade da equação de risco.
Por que não apenas dados estatísticos puros?
Os resultados nos dados são limitados principalmente ao que podemos testar de maneira automatizada. Fale com um profissional experiente da AppSec, e ele lhe contará sobre as coisas que encontrou e as tendências que viu e que ainda não constaram dos dados. Leva tempo para as pessoas desenvolverem metodologias de teste para certos tipos de vulnerabilidade e mais tempo para que esses testes sejam automatizados e executados em uma grande população de aplicativos. Tudo o que encontramos é uma retrospectiva e pode estar faltando tendências do ano passado, que não estão presentes nos dados.
Portanto, escolhemos apenas oito das dez categorias dos dados porque estão incompletos. As outras duas categorias são da pesquisa do setor. Ele permite que os profissionais nas linhas de frente votem naquilo que consideram os maiores riscos que podem não estar nos dados (e podem nunca ser expressos nos dados).
Por que taxa de incidência em vez de frequência?
Existem três fontes principais de dados. Nós os identificamos como Ferramentas Assistidas por Humanos (HaT), Ferramentas Humanas Assistidas (TaH) e Ferramentas Brutas.
Tooling e HaT são geradores de localização de alta frequência. As ferramentas procurarão vulnerabilidades específicas e tentarão incansavelmente encontrar todas as instâncias dessa vulnerabilidade e gerarão contagens de descoberta altas para alguns tipos de vulnerabilidade. Observe o Cross-Site Scripting, que normalmente é um de dois sabores: é um erro menor e isolado ou um problema sistêmico. Quando é um problema sistêmico, a contagem de descobertas pode chegar aos milhares para um aplicativo. Essa alta frequência abafa a maioria das outras vulnerabilidades encontradas em relatórios ou dados.
O TaH, por outro lado, encontrará uma gama mais ampla de tipos de vulnerabilidade, mas em uma frequência muito menor devido às restrições de tempo. Quando os humanos testam um aplicativo e veem algo como Cross-Site Scripting, eles normalmente encontram três ou quatro instâncias e param. Eles podem determinar um achado sistêmico e escrevê-lo com uma recomendação para corrigir em uma escala de aplicativo. Não há necessidade (ou tempo) para localizar todas as instâncias.
Suponha que pegemos esses dois conjuntos de dados distintos e tentemos mesclá-los na frequência. Nesse caso, os dados de Tooling e HaT irão afogar os dados TaH mais precisos (mas amplos) e é uma boa parte do motivo pelo qual algo como Cross-Site Scripting foi tão bem classificado em muitas listas quando o impacto é geralmente de baixo a moderado. É por causa do grande volume de descobertas. (Cross-Site Scripting também é razoavelmente fácil de testar, portanto, há muitos outros testes para ele também).
Em 2017, introduzimos o uso da taxa de incidência para dar uma nova olhada nos dados e mesclar os dados de Tooling e HaT com os dados TaH. A taxa de incidência pergunta qual porcentagem da população do aplicativo tinha pelo menos uma instância de um tipo de vulnerabilidade. Não nos importamos se foi pontual ou sistêmico. Isso é irrelevante para nossos propósitos; só precisamos saber quantos aplicativos tiveram pelo menos uma instância, o que ajuda a fornecer uma visão mais clara dos resultados de teste em vários tipos de teste, sem afogar os dados em resultados de alta frequência.
Qual é o seu processo de coleta e análise de dados?
Formalizamos o processo de coleta de dados OWASP Top 10 no Open Security Summit em 2017. OWASP Top 10 líderes e a comunidade passaram dois dias trabalhando na formalização de um processo transparente de coleta de dados. A edição de 2021 é a segunda vez que usamos essa metodologia.
Publicamos uma chamada para dados através dos canais de mídia social disponíveis para nós, projeto e OWASP. Na página do Projeto OWASP , listamos os elementos de dados e a estrutura que estamos procurando e como enviá-los. No projeto GitHub , temos arquivos de exemplo que servem como modelos. Trabalhamos com as organizações conforme necessário para ajudar a descobrir a estrutura e o mapeamento para os CWEs.
Obtemos dados de organizações que estão testando fornecedores por comércio, fornecedores de recompensa por bug e organizações que contribuem com dados de teste internos. Assim que tivermos os dados, nós os carregamos juntos e executamos uma análise fundamental do que os CWEs mapeiam para as categorias de risco. Há sobreposição entre alguns CWEs e outros estão intimamente relacionados (por exemplo, vulnerabilidades criptográficas). Quaisquer decisões relacionadas aos dados brutos enviados são documentadas e publicadas para serem abertas e transparentes com a forma como normalizamos os dados.
Examinamos as oito categorias com as taxas de incidência mais altas para inclusão no Top 10. Também examinamos os resultados da pesquisa do setor para ver quais já podem estar presentes nos dados. Os dois primeiros votos que ainda não estão presentes nos dados serão selecionados para os outros dois lugares no Top 10. Uma vez que todos os dez foram selecionados, aplicamos fatores generalizados para explorabilidade e impacto; para ajudar a classificar os 10 primeiros em ordem.
Fatores de dados
Existem fatores de dados listados para cada uma das 10 principais categorias, eis o que eles significam:
- CWEs mapeados : o número de CWEs mapeados para uma categoria pela equipe dos 10 principais.
- Taxa de incidência : a taxa de incidência é a porcentagem de aplicativos vulneráveis a esse CWE da população testada por essa organização naquele ano.
- (Teste) Cobertura : A porcentagem de aplicativos testados por todas as organizações para um determinado CWE.
- Exploit ponderado : A sub-pontuação do Exploit das pontuações CVSSv2 e CVSSv3 atribuídas aos CVEs mapeados para CWEs, normalizados e colocados em uma escala de 10pt.
- Impacto ponderado : A sub-pontuação de impacto das pontuações CVSSv2 e CVSSv3 atribuídas aos CVEs mapeados para CWEs, normalizados e colocados em uma escala de 10pt.
- Total de ocorrências : número total de aplicativos encontrados com os CWEs mapeados para uma categoria.
- Total de CVEs : número total de CVEs no banco de dados NVD que foram mapeados para os CWEs mapeados para uma categoria.
Relacionamentos de categoria de 2017
Muito se tem falado sobre a sobreposição entre os Dez principais riscos. Pela definição de cada um (lista de CWEs incluída), realmente não há qualquer sobreposição. No entanto, conceitualmente, pode haver sobreposição ou interações com base na nomenclatura de nível superior. Os diagramas de Venn são muitas vezes usados para mostrar sobreposições como essa.
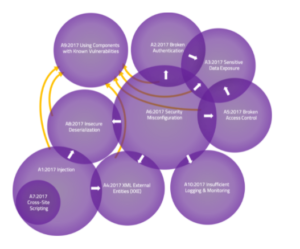
O diagrama de Venn acima representa as interações entre as dez principais categorias de risco de 2017. Ao fazer isso, alguns pontos essenciais tornaram-se óbvios:
- Pode-se argumentar que o Cross-Site Scripting, em última análise, pertence à Injection, pois é essencialmente a Injection de conteúdo. Observando os dados de 2021, ficou ainda mais evidente que o XSS precisava passar para a injeção.
- A sobreposição é apenas em uma direção. Freqüentemente, classificaremos uma vulnerabilidade pela manifestação final ou “sintoma”, não pela causa raiz (potencialmente profunda). Por exemplo, “Exposição de dados confidenciais” pode ter sido o resultado de uma “configuração incorreta de segurança”; entretanto, você não o verá na outra direção. Como resultado, setas são desenhadas nas zonas de interação para indicar em qual direção ela ocorre.
- Às vezes, esses diagramas são desenhados com tudo em A06: 2021 Usando componentes com vulnerabilidades conhecidas . Embora algumas dessas categorias de risco possam ser a causa raiz de vulnerabilidades de terceiros, elas geralmente são gerenciadas de maneira diferente e com responsabilidades diferentes. Os outros tipos geralmente representam riscos primários.
Fonte: https://owasp.org/Top10/?utm_campaign=20210914_g-hash_-_ed_080&utm_medium=email&utm_source=RD+Station
A SAFEWAY é uma empresa de Segurança da Informação, reconhecida pelos seus clientes por oferecer soluções de alto valor agregado, através de projetos em Segurança da Informação que atendam integralmente às necessidades do negócio.
Nesses anos de experiência, acumulamos, com muito orgulho, diversos projetos de sucesso que nos renderam credibilidade e destaque em nossos clientes, os quais constituem em grande parte, as 100 maiores empresas do Brasil.
Hoje através de mais de 23 parcerias estratégicas com fabricantes globais e de nosso SOC, a SAFEWAY é considerada uma one stop shopping com as melhores soluções de tecnologia, processos e pessoas.
A SAFEWAY pode ajudar sua organização através do SAFEWAY SECURITY TOWER uma cadeia de serviços completa para que suas operações continuem a serem monitoradas e protegidas por um time altamente especializado. Nosso SOC funciona em regime 24×7, contando com uma equipe técnica de alta performance e ferramentas para auxiliar a sua organização na identificação e resposta a incidentes de forma preditiva e reativa, mantendo o seu negócio seguro e monitorado em todos os momentos.
Vamos tornar o mundo um lugar mais seguro para viver e fazer negócios!


